21 Javascript Scraper Client Side
CodinGame is a challenge-based training platform for programmers where you can play with the hottest programming topics. Solve games, code AI bots, learn from your peers, have fun.
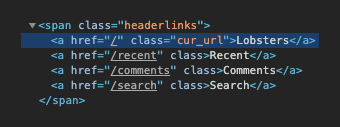 Scrape Sever Side Rendered Html Content With Javascript
Scrape Sever Side Rendered Html Content With Javascript
6/10/2020 · Scrape client-side rendered HTML content with JavaScript. In a previous tutorial I wrote about scraping server-side rendered HTML content. Many modern websites however are rendered client-side so a different approach to scraping them is required. Enter Puppeteer a Node.js library for running a headless Chrome browser.

Javascript scraper client side. So-called 'client-side dynamic rendering' gives clients cool experiences, but makes it harder for machines to comprehend. In case you want to do data mining, scrape websites or send static versions of your slick single-page application to Altavista, you essentially need a browser in the loop. Code language: JavaScript (javascript) In this example i'll be using https://lobste.rs/ as the data source to be scraped. Inspecting the code the site name in the header has a cur_url class so let's see if we can scrape it's text: Add the following to scrape.js to fetch the HTML and log the title text if successful: Jun 17, 2014 -
Scraping Ajax Pages (Advanced) One of the fundamental (and frustrating) differences between a web scraper and a web browser is the ability to execute client-side code, such as JavaScript. This isn't usually a problem, but JavaScript can sometimes be used to encode or hide data that makes it difficult to get at for a web scraper. Or check out the Github project page.. Start consuming API#. In order to get API key you'll need to register at ScrapingAnt Service. Usage of ScrapingAnt API client is quite straight forward, as it supports all the input and output describe at Request and response format page.Below you can find an example of it's usage: CORS or Cross-Origin Resource Sharing, can be a real problem with client-side web scraping. For security reasons, browsers restrict cross-origin HTTP requests initiated from within scripts. And because we are using client-side Javascript on the front end for web scraping, CORS errors can occur.
With client-side JavaScript, you can set a breakpoint right where it sets the value. This breakpoint gets hit right as the event fires. The value that gets set through var value = '2'; can change at will. The debugger halts execution and allows a person to tamper with the page. 22/7/2015 · No, you won't be able to use the browser of your clients to scrape content from other websites using JavaScript because of a security measure called Same-origin policy. There should be no way to circumvent this policy and that's for a good reason. Imagine you could instruct the browser of your visitors to do anything on any website. Apr 24, 2017 - A simple browser/client-side web scraper. Contribute to epiqueras/getsy development by creating an account on GitHub.
npm i -save axios. Then we'll want to install cheerio for the scraping which will give you the familiar syntax of Jquery. As a side note you could have installed axios and cheerio at the same time. npm i -save cheerio. We'll want to create a file to scrape in, so that's what we'll do that next. touch index.js. When they talk about client-side rendering, that means rendering content in the browser using JavaScript. So instead of getting all of the content from the HTML document itself, you are getting a bare-bones HTML document with a JavaScript file that will render the rest of the site using the browser. Asynchronicity: sandcrawler is not trying to fight the asynchronous nature of client-side JavaScript. If you want to be able to perform complex scraping tasks on modern dynamic websites, you won't be able to avoid asynchronicity anyway.
Can I implement a screen scraper app completely on the client side? That is, can javascript or similar support a http request to a 3rd party site then parse the results? I'm not wedded to any particular tech, but would like to achieve this on the client side with no additional plug-ins etc. And some tell me to run it on the ... this client side. And, why Cheerio? Isn't that for parsing the DOM. I don't need to do that. I'm happy parsing the raw string myself. ... I've just used node.js with cheerio and request, but @JavaScriptDaily tweeted this yesterday: https://github /ruipgil/scraperjs... Node.js is a cross-platform, open-source JavaScript framework that helps execute data from different websites. It is primarily used for client-side scripting, where codes and scripts are written in JavaScript and embedded in a site's HTML. Node.js allows you to use JavaScript server for producing dynamic web content.
Oct 08, 2017 - by Codemzy Client-side web scraping with JavaScript using jQuery and RegexWhen I was building my first open-source project, codeBadges, I thought it would be easy to get user profile data from all the main code learning websites. I was familiar with API calls and get requests. I thought I could The client-side scraping companion artoo.js is a piece of JavaScript code meant to be run in your browser's console to provide you with some scraping utilities. This nice droid is loaded into the JavaScript context of any webpage through a handy bookmarklet you can instantly install by dropping the above icon onto your bookmark bar. When you access a website, the JavaScript is read by the browser and changed to a couple of lines of code that the computer can process. Introducing Node.Js, the tool that helps Javascript run not only client-side but also server-side. Node.Js can be defined as a free, open-source JavaScript for server-side programming.
Most modern websites use a client-side JavaScript framework such as React, Vue or Angular. Scraping data from a dynamic website without server-side rendering often requires executing JavaScript code. I've scraped hundreds of sites, and I always use Scrapy. Scrapy is a popular Python web scraping framework. Feb 15, 2017 - The post describes my failed attempts to reach client side cross-origin resources. With javascript load html. 4/3/2009 · For example, I’ve built a site that tracks movies on the IMDb 250 by scraping content. There are libraries that simplify scraping in most languages: Perl: WWW::Mechanize; Python: BeautifulSoup; Ruby: HPricot; PHP: XPath (built-in) Javascript: jQuery on env.js on Rhino; But all of these are on the server side. That is, the program scrapes from your machine.
The Client-Side JavaScript Reference provides reference material for the JavaScript language, including both core and client-side JavaScript. If you are new to JavaScript, start with Chapter 1, "JavaScript Overview," then continue with the rest of the book. Once you have a firm grasp of the fundamentals, you can use the Client-Side JavaScript Reference to get more details on individual … Jun 15, 2018 - Since the Javascript can only be executed on the client side, a request from the page would not include it’s dynamic content. To solve this problem, you can use a browser automation tool such as Selenium or PhantomJs in combination with your web scraper script. Aug 28, 2018 - CasperJS, Puppeteer, and PhantomJS are probably your best bets out of the 6 options considered. This page is powered by a knowledgeable community that helps you make an informed decision.
The first thing that happens when a site starts client side detection is that all scrapers that are not a real browser will get blocked immediately. The simplest check is if the client (web browser) can render a block of JavaScript. If it doesn't, the detection are pretty much flags the visitor to be a bot. artoo.js - the client-side scraping companion. Contribute to medialab/artoo development by creating an account on GitHub. Mar 02, 2021 - Learn web scraping with Javascript and NodeJS with this step-by-step tutorial. We will see the different ways to scrape the web in Javascript through lots of example.
If you're using JavaScript for scraping, you should go straight to the logical conclusion and run your scraper inside a real browser (potentially headless) - using Puppeteer or Selenium or Playwright. CORS or Cross-Origin Resource Sharing, can be a real problem with client-side web scraping. For security reasons, browsers restrict cross-origin HTTP requests initiated from within scripts. And... pjscrapeis a framework for anyone who's ever wanted a command-line tool for web scraping using Javascript and jQuery. Built to run with PhantomJS, it allows you to scrape pages in a fully rendered, Javascript-enabled context from the command line, no browser required.
Resource scrapers# amazon-scraper: Useful tool to scrape product information from the amazon; app-store-scraper: Node.js module to scrape application data from the iTunes/Mac App Store. instagram-scraper: Since Instagram has removed the option to load public data through its API, this actor should help replace this functionality. Server-Side Rendering (SSR): It is a standard rendering strategy, essentially the majority of your web page's assets are housed on the server. At that point, when the page is requested, the HTML is conveyed to the browser and rendered, JS and CSS downloaded, and the last render appears to the client/bot/crawler. 3. It's a different use case. With puppeteer you can also scrape content that's rendered with JavaScript on the client. A lot of applications are client side only. Scraping that is not possible using curl. Also it's way easier to write DOM selectors than regular expressions.
Jun 04, 2021 - A web scraper represents the tool that will help us automate the process of gathering a website’s data. Build one using JavaScript & NodeJS. Here are the steps for creating the scraping logic: 1. Let's start by creating a file called index.js that will contain the programming logic for retrieving data from the web page. 2. Then, let's use the require function, which is built-in within Node.js, to include the modules we'll use in the project.
Scraping example of server-side rendered web page - Parse HTML in Excel VBA - Learn by parsing hacker news home page. In Client side rendering, only HTML layout is sent by the server along with Javascript files > Data is pulled from a different source or an API using Javascript and rendered on your browser. Client-side storage. Modern web browsers support a number of ways for web sites to store data on the user's computer — with the user's permission — then retrieve it when necessary. This lets you persist data for long-term storage, save sites or documents for offline use, retain user-specific settings for your site, and more. All 532 Python 275 JavaScript 76 Jupyter Notebook 31 Go 21 Ruby ... 🚀 Stealth - Secure, Peer-to-Peer, Private and Automateable Web Browser/Scraper/Proxy. web-scraper anonymity web ... A simple browser/client-side web scraper. scraper browser web-scraper client-side ...
Jul 26, 2020 - However, our scraping tool will most likely only see the empty HTML shell and not be able to make the additional request as our browser does. Even if we tune our scraper to make additional requests, the scraping process can become slow. This is also why SPA and client side rendered websites ... Jul 24, 2017 - I've been searching for a few days and I understand CORS requests and such. Basically I have some web scrapers running in AWS Lambda (node.js … In simple words, each time you make a call to the web scraping API, ScrapingAnt runs a headless Chrome and opens the target URL via one of the proxies. Such a scheme allows you to avoid blocking and rate-limiting, so your web scraper will always receive the extracted data. Here is the example of ScrapingAnt Javascript client usage:
Thanks to Node.js, JavaScript is a great language to u se for a web scraper: not only is Node fast, but you'll likely end up using a lot of the same methods you're used to from querying the ... 6/8/2021 · Caterpillar is the ultimate logging system for Deno, Node.js, and Web Browsers. Log levels are implemented to the RFC standard. Log entries can be filtered and piped to various streams, including coloured output to the terminal, the browser's console, and …

 Web Scraper Apify
Web Scraper Apify
Github Dsalin Shamelessjs Universal Web Page Scraper For
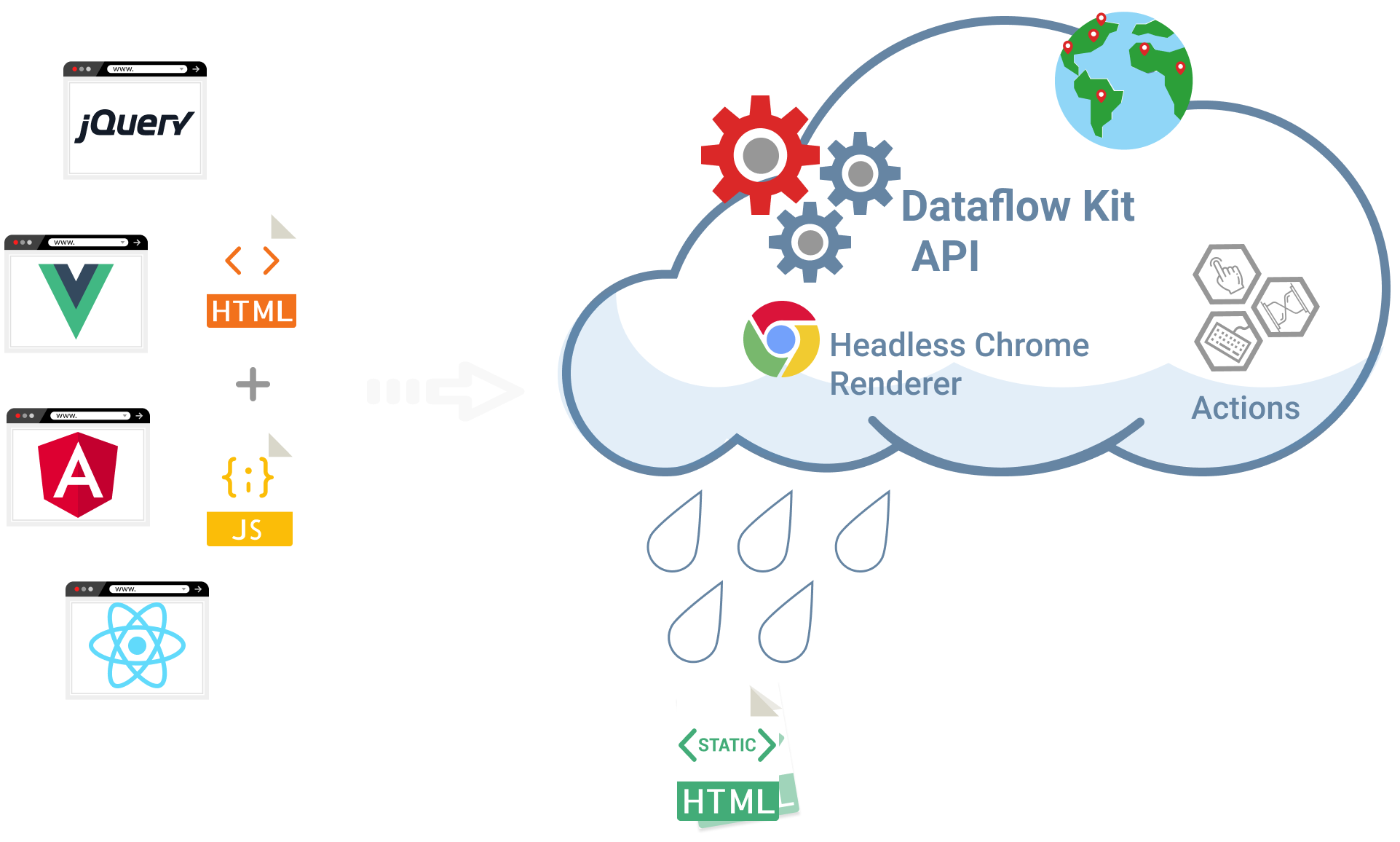 Html Scraping Render Javascript With Headless Chrome In The
Html Scraping Render Javascript With Headless Chrome In The
 Web Scraping With Javascript Nodejs Scrapingant Blog
Web Scraping With Javascript Nodejs Scrapingant Blog
 Web Scraping With Javascript The Company I Work For Just
Web Scraping With Javascript The Company I Work For Just
 Semalt Is Jquery The Best Javascript Library For Screen
Semalt Is Jquery The Best Javascript Library For Screen
 Headless Browser Examples With Puppeteer Toptal
Headless Browser Examples With Puppeteer Toptal
How To Build A Web Scraper With Javascript And Node Js Geosurf
 Web Scraping Best Practices Scraperapi Cheat Sheet Scraperapi
Web Scraping Best Practices Scraperapi Cheat Sheet Scraperapi
 Client Side Web Scraping With Javascript Using Jquery And Regex
Client Side Web Scraping With Javascript Using Jquery And Regex
 Building A Full Stack Web Scraping App With Javascript
Building A Full Stack Web Scraping App With Javascript

 How To Scrape Web Applications In Node Js Using Cheerio By
How To Scrape Web Applications In Node Js Using Cheerio By
 How To Build A Web Scraper With Javascript And Node Js Geosurf
How To Build A Web Scraper With Javascript And Node Js Geosurf
 How To Build A Web Scraper With Node Js Proxycrawl Blog
How To Build A Web Scraper With Node Js Proxycrawl Blog
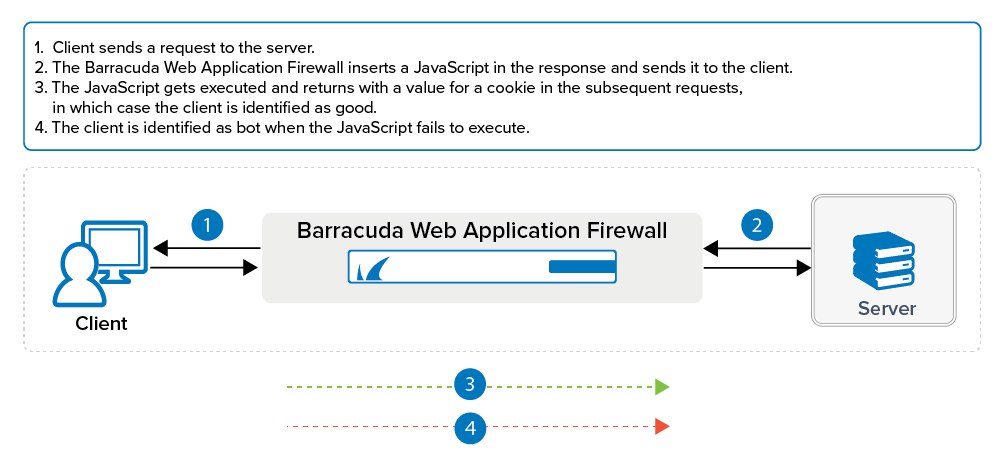 How To Configure A Web Scraping Policy Barracuda Campus
How To Configure A Web Scraping Policy Barracuda Campus
 How To Build A Concurrent Web Scraper With Puppeteer Node Js
How To Build A Concurrent Web Scraper With Puppeteer Node Js
 Scraping The Web With Javascript Vishwasa Navada K
Scraping The Web With Javascript Vishwasa Navada K
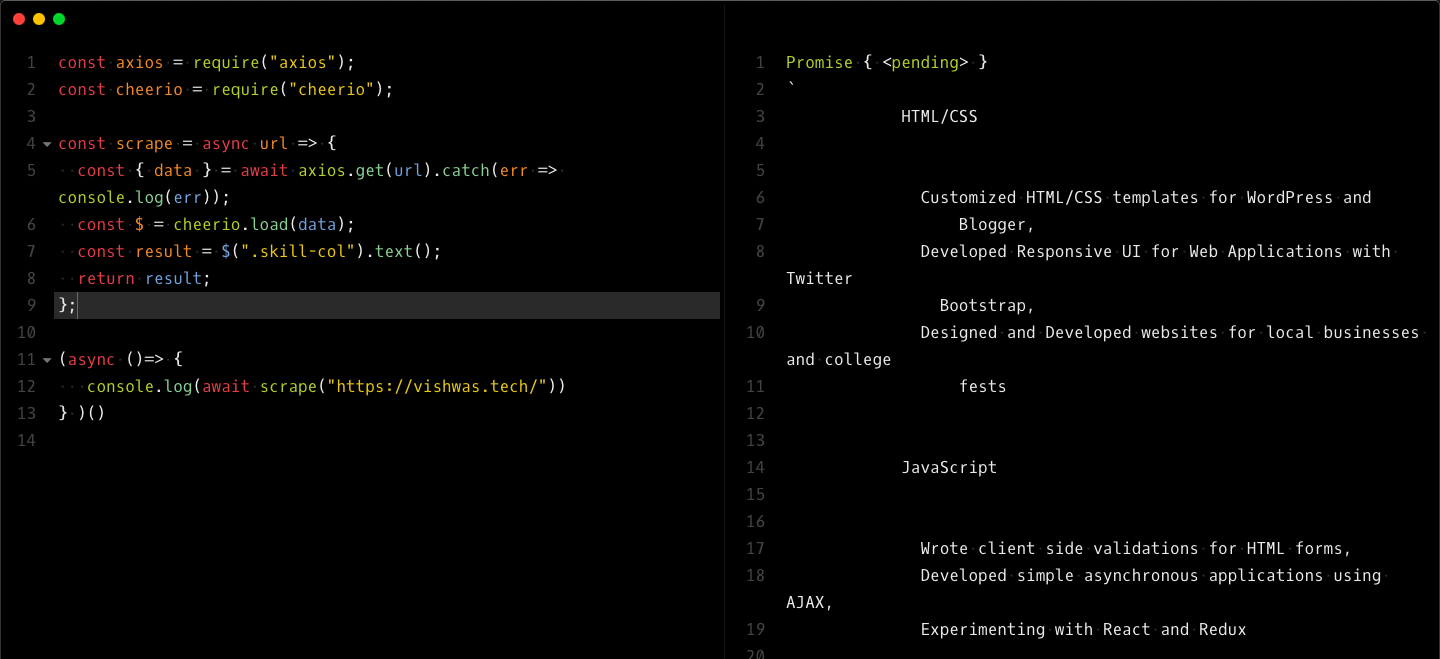 Scraping The Web With Javascript Vishwasa Navada K
Scraping The Web With Javascript Vishwasa Navada K
0 Response to "21 Javascript Scraper Client Side"
Post a Comment