34 How To Crawl Data From A Website Using Javascript
Jun 02, 2019 - So what’s web scraping anyway? It involves automating away the laborious task of collecting information from websites. There are a lot of use cases for web scraping: you might want to collect prices from various e-commerce sites for a price comparison site. Or perhaps you need flight times and This article discusses how to scrape data from dynamic websites that reveal tabulated data through a JavaScript instance.
 Web Scraper Apify Documentation
Web Scraper Apify Documentation
Using the Goutte CSS Selector component and the option to click on a page, you can easily crawl an entire website with several pages and extract as much data as you need. Web Scraping in PHP with Simple HTML DOM. Simple HTML DOM is another minimalistic PHP web scraping library that you can use to crawl a website. Let's discuss how you can use ...
How to crawl data from a website using javascript. Oct 08, 2017 - by Codemzy Client-side web scraping with JavaScript using jQuery and RegexWhen I was building my first open-source project, codeBadges, I thought it would be easy to get user profile data from all the main code learning websites. I was familiar with API calls and get requests. I thought I could Let's take the example of a video game website: Instant Gaming. Our objective: Recover the data from the video games (on Xbox) put on sale on the website and compile them a JSON file. It can then be reused in projects (example: A Chrome extension that can display this list in real time). This is what our file example-crawl.js contains. DeepCrawl can now crawl JavaScript websites by using our page rendering service (PRS) feature. This release allows us to analyse the technical health of JavaScript websites or Progressive Web Apps (PWAs). Page Rendering Service (PRS) DeepCrawl can use the page rendering service to execute JavaScript just like modern search engines.
Here are the basic steps to build a crawler: Step 1: Add one or several URLs to be visited. Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread. Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API. Step 4: Parse all the URLs present on the page, and add them to ... 1 week ago - Crawling websites is not quite as straightforward as it was a few years ago, and this is mainly due to the rise in usage of JavaScript frameworks, such as Angular and React. Traditionally, a crawler would work by extracting data from static HTML code, and up until relatively recently, most ... Jun 30, 2015 - Quora is a place to gain and share knowledge. It's a platform to ask questions and connect with people who contribute unique insights and quality answers.
Web scraping is an amazing way to gather much data with comparably low effort. Using and analyzing the collected data may provide advantages on a competition aspect and gives great insights on how ... getPostTitles() is an asynchronous function that will crawl the Reddit's old r/programming forum. First, the HTML of the website is obtained using a simple HTTP GET request with the axios HTTP client library. Then the HTML data is fed into Cheerio using the cheerio.load() function. Here are the main tips on how to crawl a website without getting blocked: 1. Check robots exclusion protocol. Before crawling or scraping any website, make sure your target allows data gathering from their page. Inspect the robots exclusion protocol (robots.txt) file and respect the rules of the website. Even when the web page allows crawling ...
Sep 27, 2020 - From the point I started to learn about web development I was enthusiastic about web crawling. Most of the time it is called “web crawling”, “web scraping” or “web spider”. Going through the web and… Parsehub is a web crawler that collects data from websites using AJAX technology, JavaScript, cookies and etc. Its machine learning technology can read, analyze and then transform web documents into relevant data. Jan 27, 2017 - Since JavaScript is increasingly ... in JavaScript. Here's my first attempt at a web crawler. I was able to do it in about 70 lines of code. The full code is included at the bottom with plenty of comments breaking it down and explaining each step. Maybe in future posts I'll have it connect to a database and store ...
Web crawling is a powerful technique to collect data from the web by finding all the URLs for one or multiple domains. Python has several popular web crawling libraries and frameworks. In this article, we will first introduce different crawling strategies and use cases. Then we will build a simple web crawler from scratch in Python using two ... Feb 03, 2019 - Let’s learn how to scrape data quickly with some free tools as cheerio and jsonframe using javascript. Sep 06, 2018 - Extra information can be retrieved from the rest of the page fields: error, response, body which are identical to the ones passed to the callback of request invocation of the Request module. referer field will reference the url of the page that lead the crawler to the current page.
After successfully running the code, there is a file named data.txt also which has all the data extracted! we can find this file in our project directory. So, it is a simple example of how to create a web scraper in nodejs using cheerio module. From here, you can try to scrap any other website of your choice. To crawl a JavaScript website, open up the SEO Spider, click 'Configuration > Spider > Rendering' and change 'Rendering' to 'JavaScript'. 2) Check Resources & External Links Ensure resources such as images, CSS and JS are ticked under 'Configuration > Spider'. Generally, browser JavaScript can only crawl within the domain of its origin, because fetching pages would be done via Ajax, which is restricted by the Same-Origin Policy.
Aug 13, 2020 - In this tutorial, you will build a web scraping application using Node.js and Puppeteer. Your app will grow in complexity as you progress. First, you will code your app to open Chromium and load a special website designed as a web-scraping sandbox: bo In the past, retrieving data from another domain involved the XMLHttpRequest or XHR object. Nowadays, we can use JavaScript's Fetch API. The fetch () method. It takes one mandatory argument — the... A JavaScript crawl executes JavaScript (JS) however an non-JS-crawl does not. Having JavaScript execute on a website can result in different content being seen during the crawl than when JavaScript is not executed. This is comparable to the difference between the content seen on a website page when JavaScript is enabled or disabled on your browser.
Easy to use API to crawl and scrape websites. Crawler. For large scale projects that require large amounts of data. Scraper API. Get structured data for your business. Screenshots API. Take screenshots of websites as images with an API. The data crawled can be used for evaluation or prediction in different fields. Here, I'd like to talk about 3 methods we can adopt to crawl data from a website. 1. Use Website APIs. Many large social media websites, like Facebook, Twitter, Instagram, StackOverflow provide APIs for users to access their data. After selecting the required page, click on "Get Data" on the left side to crawl the webpage. The following window will appear: Click on "Run" and the program will ask for the data type you wish to download. Select the required type and the program will ask for the destination folder.
Dec 28, 2020 - JavaScript SEO – How to Crawl JavaScript Rich Websites · SEO for JavaScript websites is considered one of the most complicated fields of technical SEO. Fortunately there is more and more data, case studies and tools to make this a little bit easier, even for technical SEO rookies. Above is a simple flow of how a web crawler scrapes data from a website. It is good to know your target website very well before getting an algorithm for scraping. You should keep in mind that depending on the target website flow might get complex but having a better flow makes you add necessary intelligence to the web crawler. If, however you want to audit a JavaScript site, you need a website crawler capable of rendering JS, to enable them to crawl and scrape SEO data from the site. If JavaScript Rendering is not enabled or not available in the web crawler tool you are using this would typically result in a failed ...
The power of Selenium is not just restricted to testing your web apps, one other use can be of crawling or scraping websites, in particular, the ones which don't provide an API and load content lazily using Javascript. We will be crawling an online merchant website www.jabong with Selenium using its python bindings. Jabong loads more ... In this Node.js web scraping tutorial, we'll demonstrate how to build a web crawler in Node.js to scrape websites and stores the retrieved data in a Firebase database. Our web crawler will perform the web scraping and data transfer using Node.js worker threads. Here's what we'll cover: A Web Crawler is a program that navigates the Web and finds new or updated pages for indexing. The Crawler starts with seed websites or a wide range of popular URLs (also known as the frontier) and searches in depth and width for hyperlinks to extract.. A Web Crawler must be kind and robust. Kindness for a Crawler means that it respects the rules set by the robots.txt and avoids visiting a ...
Web scraping is a technique used to extract data from websites using a script. Web scraping is the way to automate the laborious work of copying data from various websites. Web Scraping is generally performed in the cases when the desirable websites don't expose the API for fetching the data. Some common web scraping scenarios are: Click on the Sitemap that you just created, click on 'Add new selector'. In the selector id field, give the selector a name. In the type field, you can select the type of data that you want to be extracted. Click on the select button and select any element on the web page that you want to be extracted. Once you have a list of URLs, Click Crawl Scrape from the left side menu. Click "Load/New Crawl" from the top tabs in Data Miner. And then from the center options, click "Create new Crawl". Next we will tell Data Miner where the URLs will be coming from. This is done from the "Set URLs" Tab.
Scraping the web page using Selenium. 1. Selenium with geckodriver. Since we are unable to access the content of the web page using Beautiful Soup, we first need to set up a web driver in our python script. # import libraries. import urllib.request. from bs4 import BeautifulSoup. from selenium import webdriver. import time. A quick-fire guide on how to crawl JavaScript websites in the Screaming Frog SEO Spider tool (https://www.screamingfrog.co.uk/crawl-javascript-seo/) Apr 12, 2021 - That’s where our new High-Performance Crawler can help. It can execute, render and crawl JavaScript to give you the data you need to ensure that your dynamic website is free of mistakes. We use an optimized Chrome browser to render JavaScript like you do with your browser.
Oncrawl can crawl the website with JavaScript code. This tool can handle robot.txt, a file that tells search engines which pages on your site to crawl. You can choose two crawls to compare and measures the effect of new policies on your website. It can monitor website performance.
 Web Crawling Ajax Javascript Enabled Pages Using Java
Web Crawling Ajax Javascript Enabled Pages Using Java
 Css And Javascript Seo Grasping The Basics Debugging Errors
Css And Javascript Seo Grasping The Basics Debugging Errors
 Web Scraping In Python Python Scrapy Tutorial
Web Scraping In Python Python Scrapy Tutorial
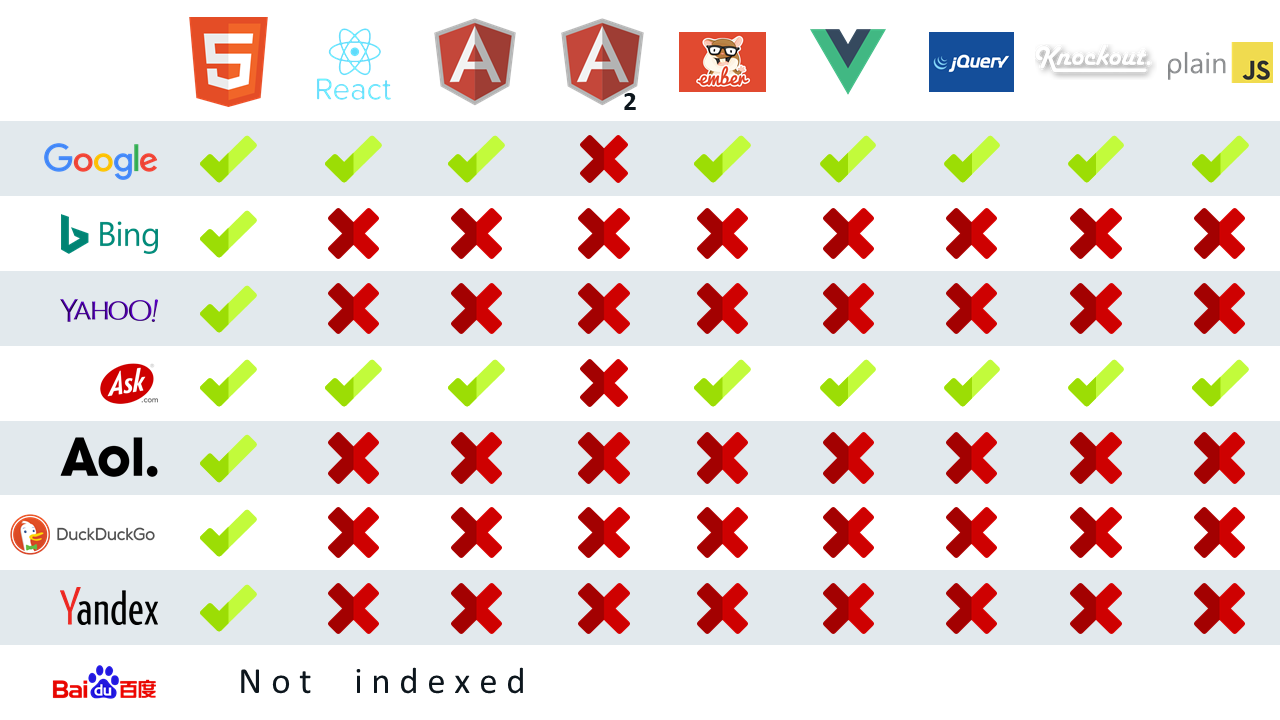
 Can Google Properly Crawl And Index Javascript Frameworks A
Can Google Properly Crawl And Index Javascript Frameworks A
 How Does Google Handle Javascript When Crawling Rendering
How Does Google Handle Javascript When Crawling Rendering
Advanced Python Web Scraping Best Practices Amp Workarounds
 Javascript Crawling For Better Amp More Accurate Site Audits
Javascript Crawling For Better Amp More Accurate Site Audits
 Getting Started With Apify Scrapers Apify Documentation
Getting Started With Apify Scrapers Apify Documentation
 The Ultimate Guide To Web Scraping With Javascript And Node Js
The Ultimate Guide To Web Scraping With Javascript And Node Js
 How To Build A Web Scraper With Javascript And Node Js Geosurf
How To Build A Web Scraper With Javascript And Node Js Geosurf
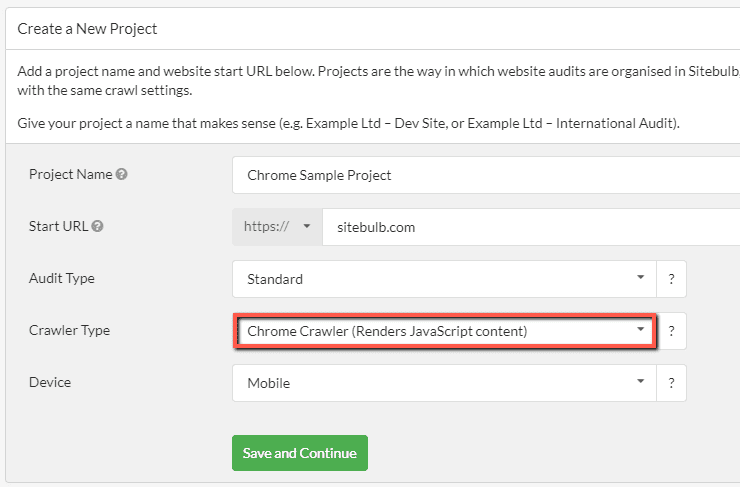 How To Crawl Javascript Websites Sitebulb Com
How To Crawl Javascript Websites Sitebulb Com
 Beautiful Soup Build A Web Scraper With Python Real Python
Beautiful Soup Build A Web Scraper With Python Real Python
 Using Javascript To Publish Content Here Are 6 Ways To View
Using Javascript To Publish Content Here Are 6 Ways To View
 Javascript And Seo The Difference Between Crawling And
Javascript And Seo The Difference Between Crawling And

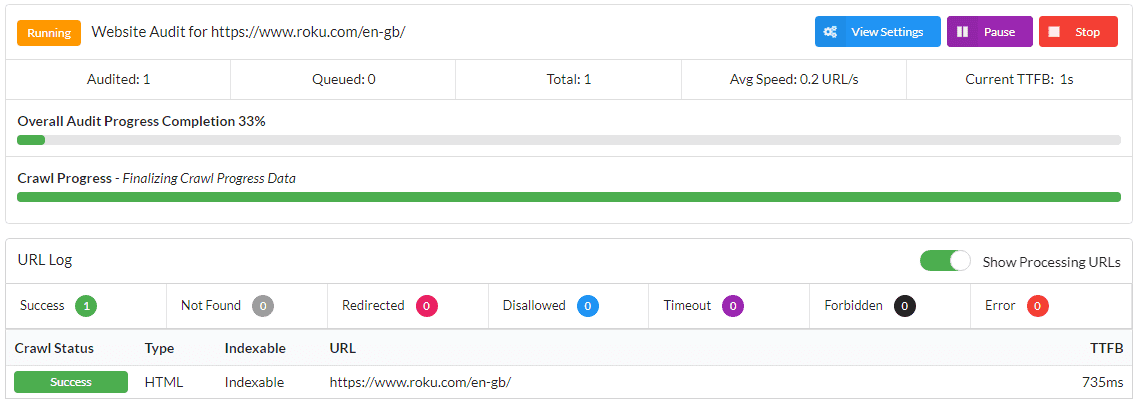 How To Crawl Javascript Websites Sitebulb Com
How To Crawl Javascript Websites Sitebulb Com
 Scraping Data In 3 Minutes With Javascript By Gabin
Scraping Data In 3 Minutes With Javascript By Gabin
 Page Rendering Service How Deepcrawl Crawls Javascript Websites
Page Rendering Service How Deepcrawl Crawls Javascript Websites
 How To Crawl A Static Website In Javascript In 4min
How To Crawl A Static Website In Javascript In 4min
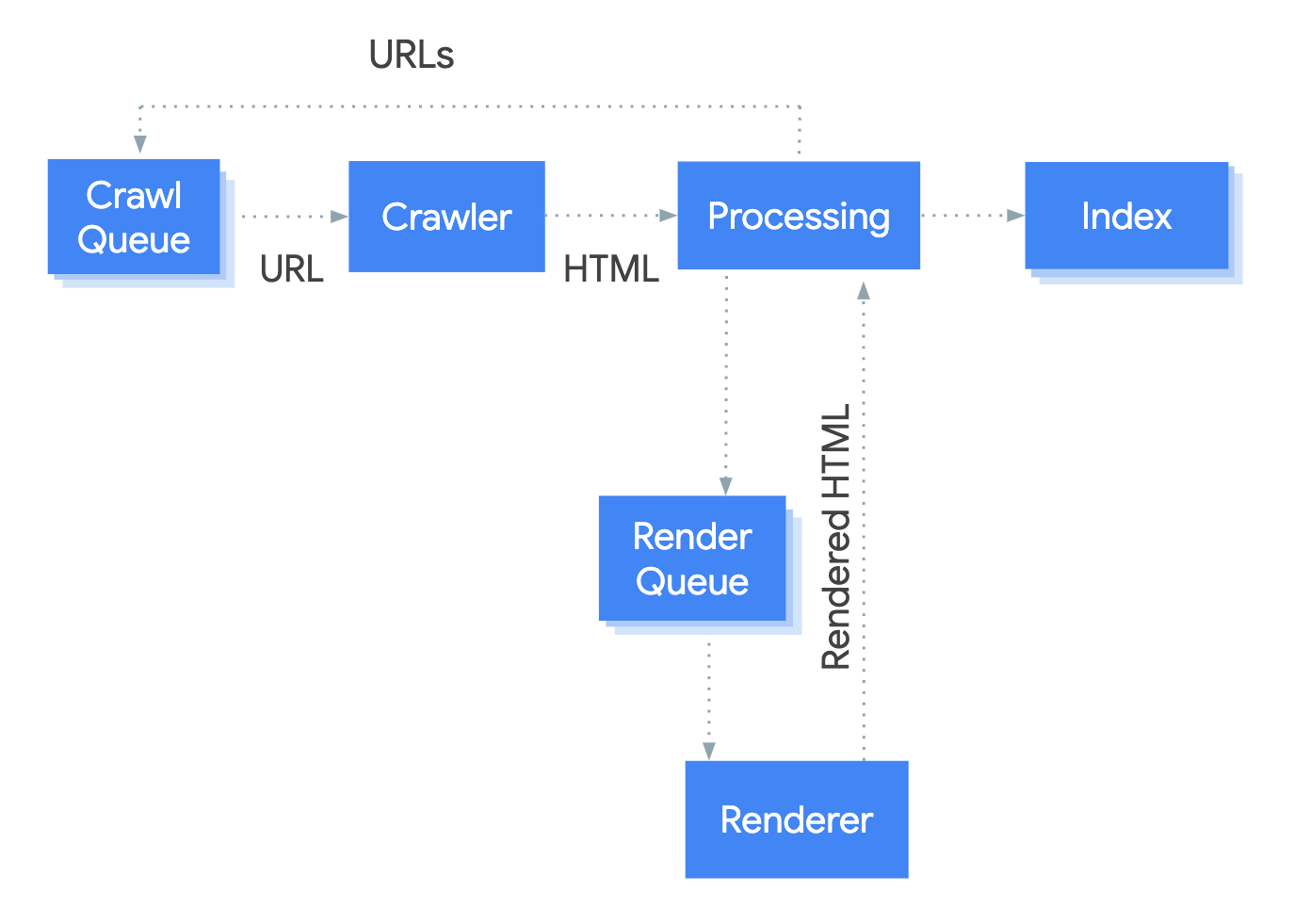 How To Crawl Javascript Websites Sitebulb Com
How To Crawl Javascript Websites Sitebulb Com
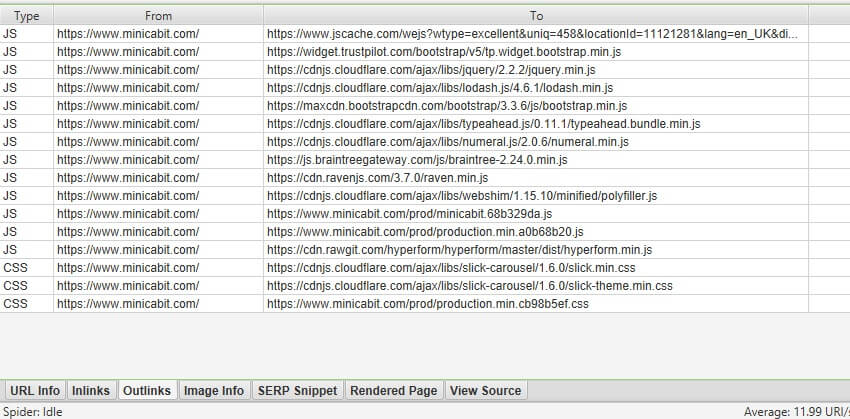 How To Crawl Javascript Websites Screaming Frog
How To Crawl Javascript Websites Screaming Frog

 Javascript Seo How To Crawl Javascript Rich Websites
Javascript Seo How To Crawl Javascript Rich Websites
 Crawling Data From Web Page With Content Rendered By
Crawling Data From Web Page With Content Rendered By
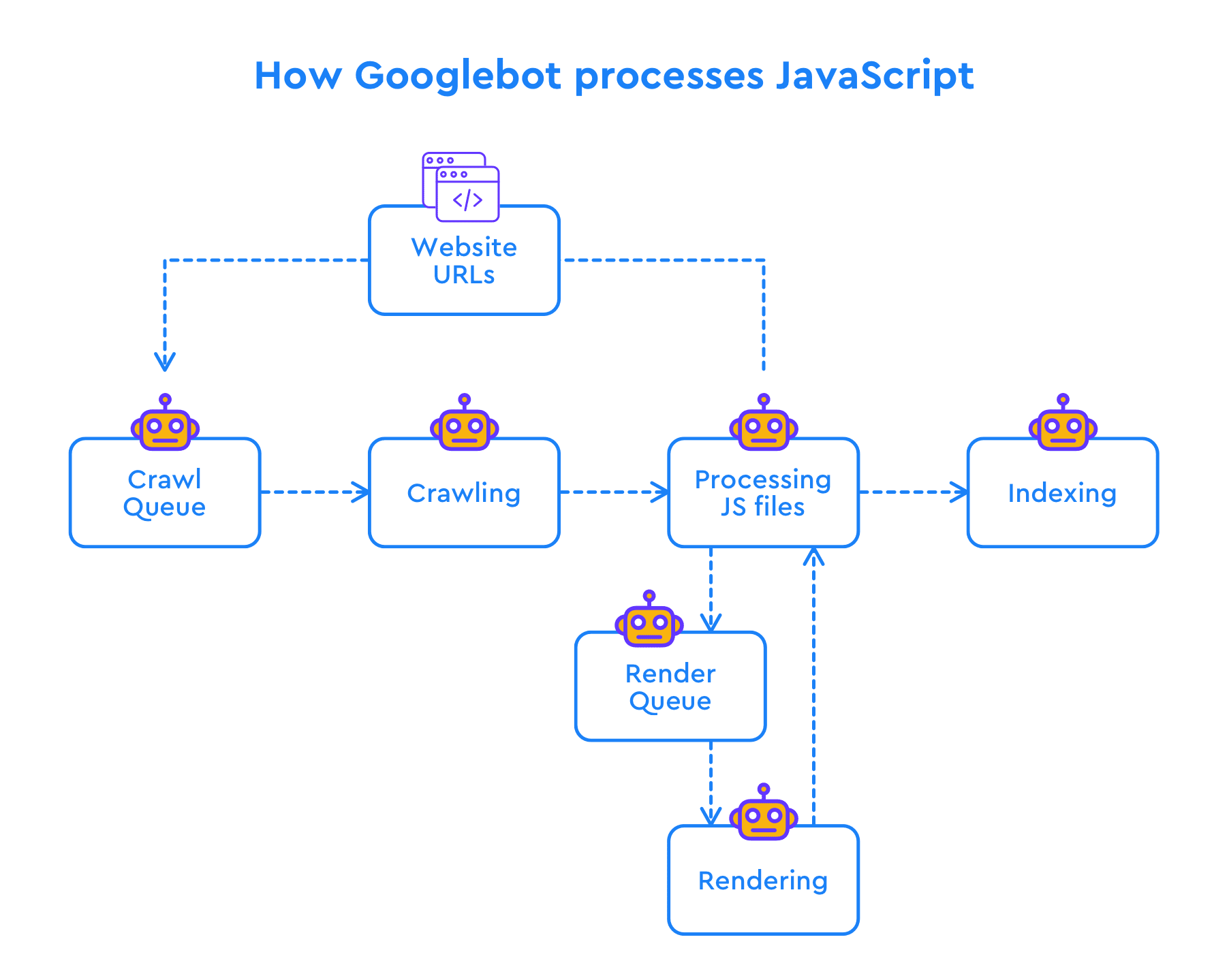
 We Tested How Googlebot Crawls Javascript And Here S What We
We Tested How Googlebot Crawls Javascript And Here S What We
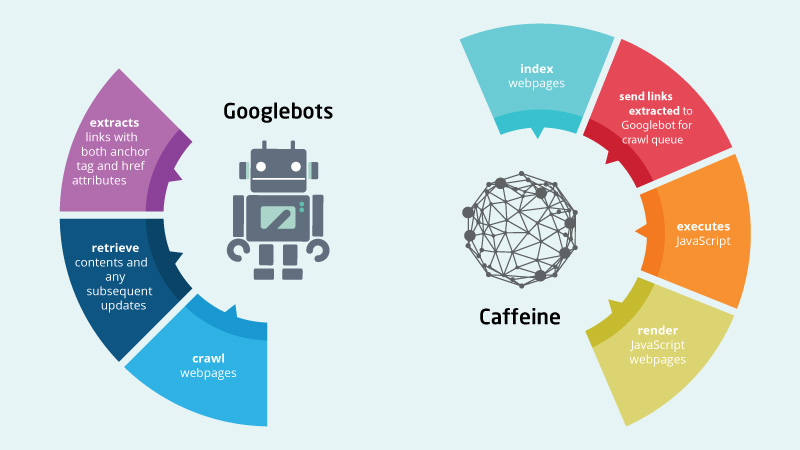 Javascript Seo How Does Google Crawl Javascript
Javascript Seo How Does Google Crawl Javascript
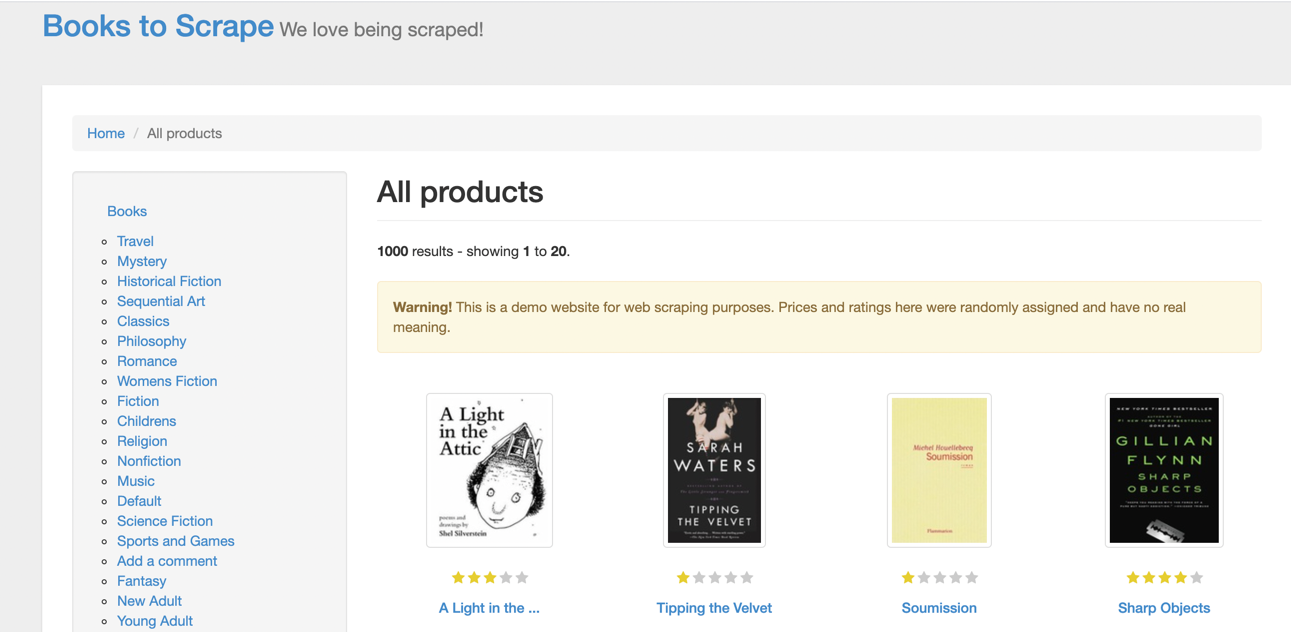 Web Scraping With Php How To Crawl Web Pages Using Open
Web Scraping With Php How To Crawl Web Pages Using Open
 Javascript Seo How To Crawl Javascript Rich Websites
Javascript Seo How To Crawl Javascript Rich Websites
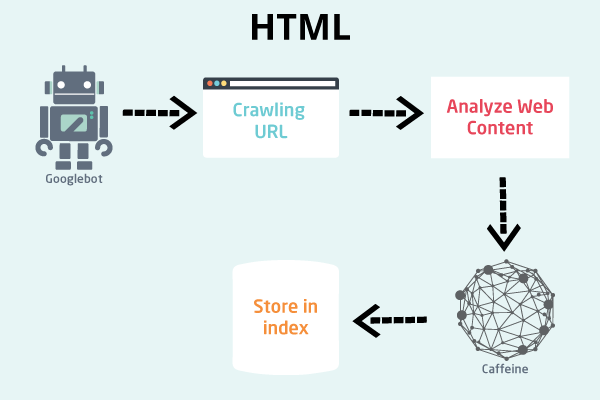 Javascript Seo How Does Google Crawl Javascript
Javascript Seo How Does Google Crawl Javascript
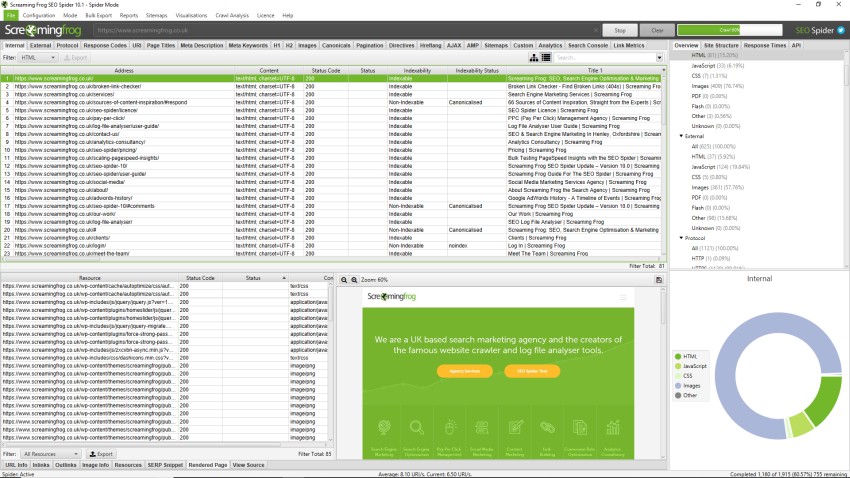 How To Crawl Javascript Websites Screaming Frog
How To Crawl Javascript Websites Screaming Frog
 Web Scraping With Javascript And Nodejs
Web Scraping With Javascript And Nodejs
 Best 3 Ways To Crawl Data From A Website Octoparse
Best 3 Ways To Crawl Data From A Website Octoparse
0 Response to "34 How To Crawl Data From A Website Using Javascript"
Post a Comment