20 Javascript Web Scraping Library
Jun 10, 2021 - Discover the 5 most popular JavaScript web scraping libraries: Axios, Nightmare, Cheerio, Puppeteer, Selenium. Which one is the best? Osmosis is considered one of the most efficient and top-notch Javascript web scraping libraries. With Osmosis, complex pages can be scraped without the knowledge and use of much coding which is just great for most of the users.
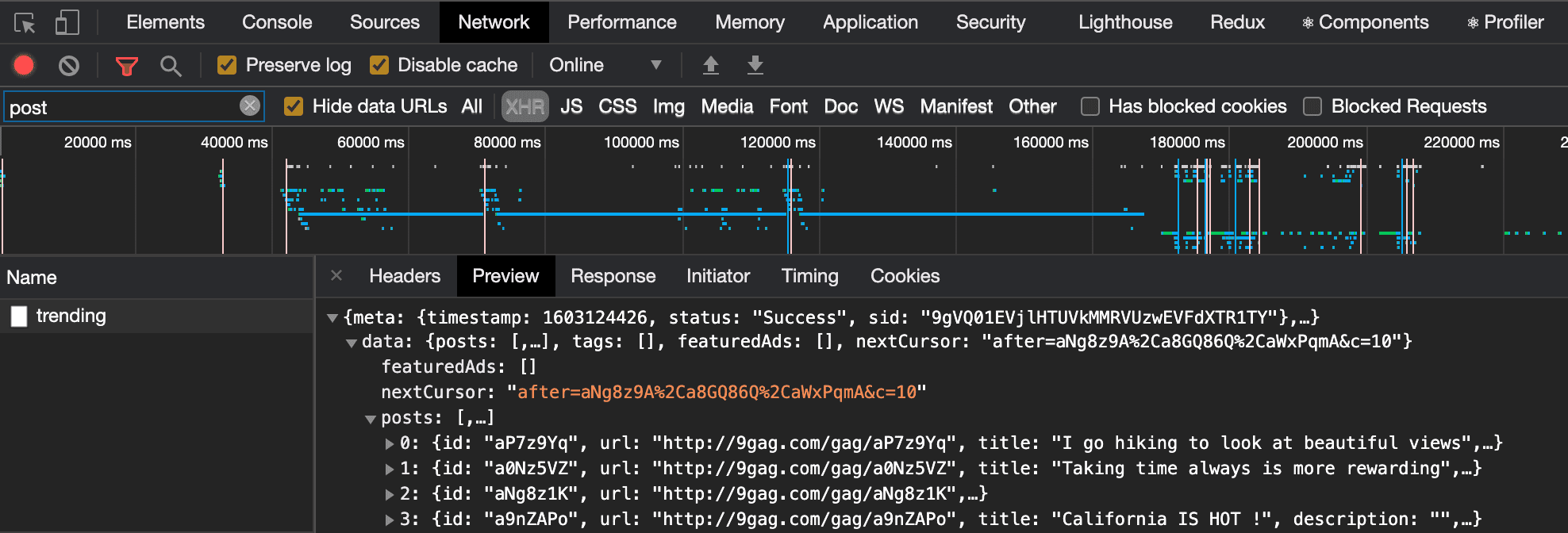 Web Scraping With Js Analog Forest
Web Scraping With Js Analog Forest
Oct 28, 2020 - Node JS is an interpreter and provides an environment for JavaScript with some specific useful libraries especially for Web Scraping

Javascript web scraping library. Disable browser fingerprinting protections used by websites. Python has Scrapy for these tasks, but there was no such library for JavaScript, the language of the web. The use of JavaScript is natural, since the same language is used to write the scripts as well as the data extraction code running in a browser. While there are various tools available for web scraping, a growing number of people spend their valuable time exploring web scraping libraries and tools for JavaScript. You might wonder why JavaScript? Why does JavaScript matter so much? Read this article to know more about JS libraries & tools Web scraping is a technique that often helps in software development. Besides web scraping techniques, knowing some regular expressions to retrieve data also important. When you want to target a website and want to scrap data, try to find a pattern. If you can discover the pattern, it's easy to implement. Check out my other web scraping ...
After installation, the next step is to install the necessary libraries/modules for web scraping. For this tutorial, I will advise you to create a new folder in your desktop and name it web scraping. Then launch Command Prompt (MS-DOS/ command line) and navigate to the folder using the command below. cd desktop/web scraper. Apify SDK - The scalable web crawling and scraping library for JavaScript. Enables development of data extraction and web automation jobs (not only) with headless Chrome and Puppeteer. Ayakashi - The next generation web scraping framework. Features all the necessary tools to create reliable and maintainable scraping and automation systems. If you want to scrape a group of news under caption, you need to change the number after news_feed/ in the request URL (to get it, you just need to filter the requests by "news_feed" in the DevTools and scroll the news page down). Sometimes web sites have protection against bots (although the website you are trying to scrape doesn't).
Jun 08, 2020 - Web scraping is a technique used for retrieving data from websites. You fetch the page’s contents, and then extract the data you need from the page for processing, saving it, or simply displaying it… jsdom. jsdom is a pure-JavaScript implementation of many web standards for Node.js, and is a great tool for testing and scraping web applications. Install it in your terminal using the following command: npm install jsdom@16.4.0. PJscrape is a web scraping framework written in Python using Javascript and JQuery. It is built to run with PhantomJS, so it allows you to scrape pages in a fully rendered, Javascript-enabled context from the command line, with no browser required. The scraper functions are evaluated in a full browser context.
There is Apify SDK - an open-source library for scalable web crawling and scraping in JavaScript. The library enables development of data extraction and web automation jobs (not only) with headless Chrome and Puppeteer. Disclaimer: This is an open-source project of my company Apify 3.1K views 6/9/2020 · jsdom is a pure-JavaScript implementation of many web standards, notably the WHATWG DOM and HTML Standards, for use with Node.js. In general, the goal of the project is to emulate enough of a subset of a web browser to be useful for testing and scraping real-world web applications. So jsdom is more than an HTML parser, it works as a browser. Web scraping with JavaScript is an automatic process that can be done on many websites at once. And below are the steps by which the process is done: ⦁ First, you find the webpage you intend to scrape. ⦁ Next, you make an HTTP request to extract the data. ⦁ The data is extracted and parsed to your device. ⦁ Finally, you save the ...
Download the response data with cURL. Write a Node.js script to scrape multiple pages. Case 2 - Server-side Rendered HTML. Find the HTML with the data. Write a Node.js script to scrape the page. Case 3 - JavaScript Rendered HTML. Write a Node.js script to scrape the page after running JavaScript. That's a wrap. Aug 20, 2019 - Web scraping is a technique used to extract data from websites using a script. Web scraping is the way to automate the laborious work of copying data from various websites. Web Scraping is generally… Since JavaScript is excellent at manipulating the DOM (Document Object Model) inside a web browser, creating data extraction scripts in Node.js can be extremely versatile. Hence, this tutorial focuses on javascript web scraping. In this article, we're going to illustrate how to perform web scraping with JavaScript and Node.js.
TL;DR: We've released the Apify SDK — an open-source Node.js library for scraping and web crawling. There was one for Python, but until now, there was no such library for JavaScript, THE language of the web. In Python there is Scrapy, the de facto standard toolkit for building web scrapers and crawlers.But in JavaScript, there was no similarly comprehensive and universal library. Web scraping is the act of using programs like Puppeteer to access and harvest data from websites programmatically. There can be legal implications for web scraping, so you should do your own research before engaging in such an action. Automating a browser is not the only way to access data on a webpage. 30/6/2020 · JS is a quite well-known language with a great spread and community support. It can be used for both client and server web scraping scripting that makes it pretty suitable for writing your scrapers and crawlers. Most of these libraries' advantages can be received by web scraping API and some of these libraries can be used in stack with it.
7/8/2018 · Getting started with web scraping is easy, and the process can be broken down into two main parts: acquiring the data using an HTML request library or a headless browser, and parsing the data to get the exact information you want. This guide will walk you through the process with the popular Node.js request-promise module, CheerioJS, and Puppeteer. A Guide to Automating & Scraping the Web with JavaScript (Chrome + Puppeteer + Node JS) ... Books to Scrape has a big library of real books and fake data on those books. What we're going to do is select the first book on the page and return the title and price of that book. Here's the homepage of Books to Scrape. Web scraping refers to the process of gather information from a website through automated scripts. With web scraping, one can gather large amounts of data from websites where no official API exists. Web scraping can be broken down into two simple steps: Fetching the HTML source code of a website via an HTTP request or a headless browser
Playwright "is a Node.js library to automate Chromium, Firefox and WebKit with a single API." When Axios is not enough, we will get the HTML using a headless browser to execute Javascript and wait for the async content to load. Scraping the Basics. The first thing we need is the HTML. We installed Axios for that, and its usage is straightforward. If you'll try to google "web scraping tutorial" you'll get a bunch of tech articles on the subject that tells you how to achieve the result using python. The toolkit is pretty standard for these posts: python 3 (hopefully not second) as an engine, requests library for fetching, and Beautiful Soup 4 (which is 6 years old) for web parsing. Scrapy is the greatest Web Scraping framework, and it was developed by a team with a lot of enterprise scraping experience. The software created on top of this library can be a crawler, scraper, and data extractor or even all this together. To install this library just execute the following PyPI command in your command prompt or Terminal:
Puppeteer — a Node library developed by Google. Proxybot — an API service for web scraping. Let's get started 👨💻. For people who prefer watching videos, there is a quick video 🎥 demonstrating how to get an HTML content of a JS-based website. Oct 05, 2018 - Quora is a place to gain and share knowledge. It's a platform to ask questions and connect with people who contribute unique insights and quality answers. JavaScript is the language of the web. Apify SDK builds on popular tools like playwright, puppeteer and cheerio, to deliver large-scale high-performance web scraping and crawling of any website. Automates any web workflow
Web Scraping with Javascript and NodeJS Shenesh Perera ● Updated: 02 March, 2021 ● 17 min read Javascript has become one of the most popular and widely used languages due to the massive improvements it has seen and the introduction of the runtime known as NodeJS. Whether it's a web or mobile application, Javascript now has the right tools. I showed you the fully functional way to scrape a JavaScript rendered web page .Apply this technique to automate any no of steps or integrate this technique and override default behavior of a scraping framework.It is slow but 100% result prone.I hope you enjoyed the post.Try now this on any website you think is tricky to scrape. All the best. Morioh is the place to create a Great Personal Brand, connect with Developers around the World and Grow your Career!
Web scraping is set to grow as time progresses. As web scraping applications abound, JavaScript libraries will grow in demand. While there are salient JavaScript libraries, it could be puzzling to choose the right one. However, it would eventually boil down to your own respective requirements. Feb 21, 2019 - It is a library that allows you to control a headless browser from a Node.js script. A perfect use case for this library is scraping pages that require JavaScript execution. Let’s examine how Puppeteer can help us scrape news headlines from r/news since the newer version of Reddit requires ... 3/6/2021 · Node.js is a fast-growing, easy-to-use runtime environment made for JavaScript, which makes it perfect for web scraping JavaScript efficiently and with a low barrier to entry. Because JavaScript is one of the most widely used and supported programming languages, it allows developers to scrape a wide variety of websites.
Web scraper for Bing. ... Lightweight scraper written in TypeScript using ES6 generators. ... Node package to pull data scraped from finance.yahoo . ... A library to easily scrape metadata from an article on the web using Open Graph, JSON+LD, regular HTML metadata, and series of fallbacks. Sep 25, 2020 - As it’s obvious, the Internet is getting overloaded with information and data. With the growth of data on the web, web scraping is also likely to become more and more important for businesses for…
 4 Tools For Web Scraping In Node Js
4 Tools For Web Scraping In Node Js
 Top 5 Javascript Web Scraping Libraries And Frameworks 2021
Top 5 Javascript Web Scraping Libraries And Frameworks 2021
 Web Scraping With Javascript And Node Js Tutorial
Web Scraping With Javascript And Node Js Tutorial
 Data Science Skills Web Scraping Javascript Using Python
Data Science Skills Web Scraping Javascript Using Python
 A Practical Introduction To Web Scraping In Python Real Python
A Practical Introduction To Web Scraping In Python Real Python
 Web Scraping And Parsing Html With Node Js And Cheerio
Web Scraping And Parsing Html With Node Js And Cheerio
 Responsible Web Scraping Gathering Data Ethically And
Responsible Web Scraping Gathering Data Ethically And
 Top 5 Javascript Web Scraping Libraries
Top 5 Javascript Web Scraping Libraries
 Create Your Own Web Scraper Using Node Js And Get Data In
Create Your Own Web Scraper Using Node Js And Get Data In
 Scraping Javascript Protected Content Web Scraping Amp Data
Scraping Javascript Protected Content Web Scraping Amp Data
 Best Web Scraping Tools Ultimate Web Scraper List Dev
Best Web Scraping Tools Ultimate Web Scraper List Dev
 Beautiful Soup Build A Web Scraper With Python Real Python
Beautiful Soup Build A Web Scraper With Python Real Python
 Best 10 Free And Paid Web Scraping Tools By Teodora C
Best 10 Free And Paid Web Scraping Tools By Teodora C
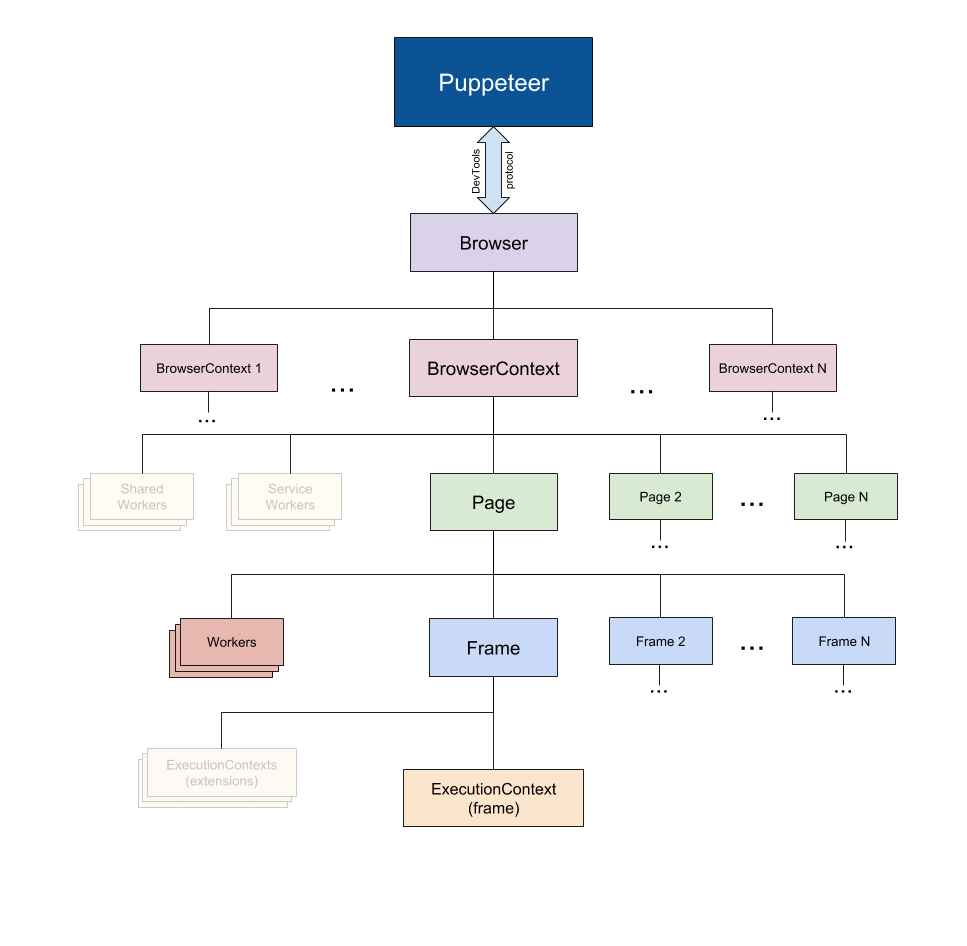 Web Scraping With Javascript And Nodejs
Web Scraping With Javascript And Nodejs
 Ultimate Guide For Scraping Javascript Rendered Web Pages
Ultimate Guide For Scraping Javascript Rendered Web Pages
Top Popular Javascript Libraries For Web Scraping In 2020
 4 Tools For Web Scraping In Node Js
4 Tools For Web Scraping In Node Js
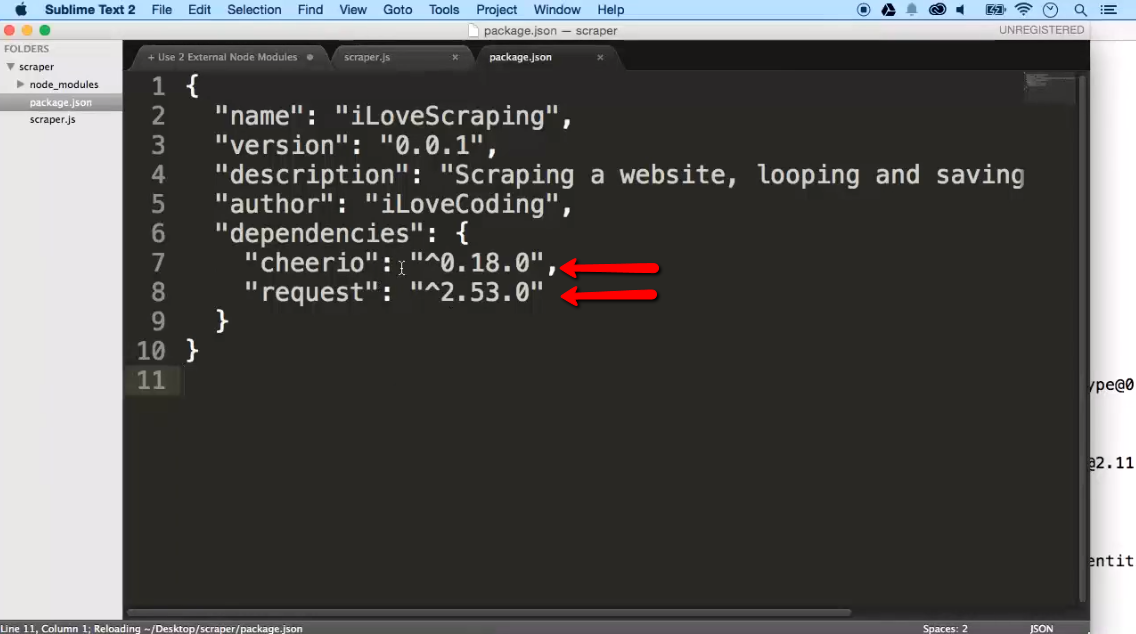 Project Create A Web Scraper To Gather Information From The
Project Create A Web Scraper To Gather Information From The
 Javascript Web Scraping Tutorials How To Scrape With
Javascript Web Scraping Tutorials How To Scrape With
0 Response to "20 Javascript Web Scraping Library"
Post a Comment